A Brief Review of Neural Network on Spoken Language Understanding
One project requires to do keyphrase extraction on scientific text. As most keyphrases appear in the text, so I am considering that whether this problem can be framed as a sequence labeling task , just like NER and POS-tagging. Recently I come across a few papers about Neural Network applications on slot filling task, a subtask of spoken language understanding. Similarly, this task also can be addressed as a a standard sequence labeling task. So I hope I can get inspired somehow from their research, and the following is some notes about these papers. It’s worth noting that this posting doesn’t cover all the Neural Network research regarding the slot filling task, mostly from MSR.
1. Task Introduction: Slot Filling and Recurrent Neural Network
A little bit of description of the slot filling task as well as the data would help you understand what’s going on here. The figure below shows an example in ATIS dataset, with the annotation of slot/concept, named entity, intent as well as domain. The latter two annotations are for the other two tasks in SLU: domain detection and intent determination. We can see that the slot filling is quite similar to the NER task, following the IOB tagging representation, except for a more specific granularity.
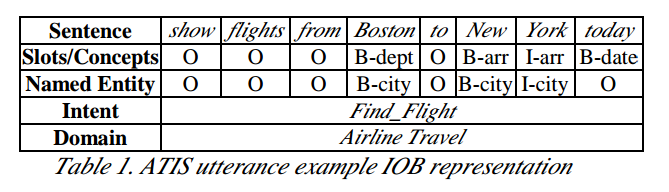
An example of IOB representation for ATIS dataset
So our task is to translate the original sentence into the IOB tagging form. Following the RNN structures shown below1, the model structure we used for sequence labeling should be the last one, which outputs a label for each input word. There are many awesome articles can offer you intuitive understanding and techniques about RNN, so I won’t refer to much detail here.
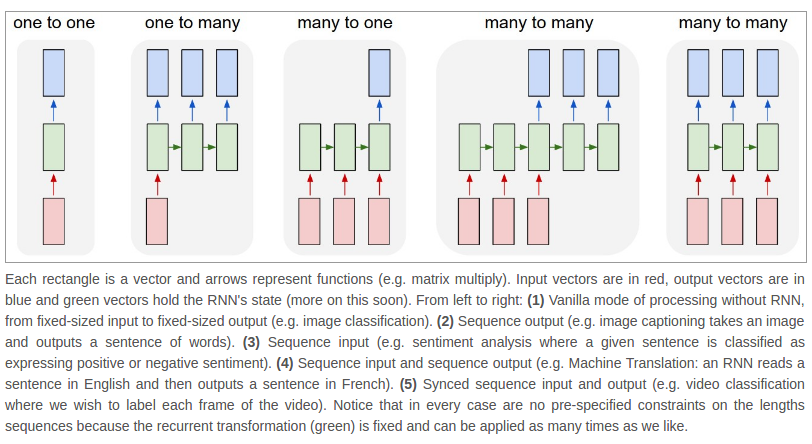
Some common architectures of recurrent neural networks
2. Paper Notes
2.1 Investigation of Recurrent-Neural-Network Architectures and Learning Methods for Spoken Language Understanding
This paper may be the first trial regarding the application of RNN on slot filling. The first author is Yoshua Bengio’s PhD student. As the RNN-based labeling method can be extended to many other tasks and it’s implemented using Theano toolkit, this work is included in the Tutorial of Theano.
Thanks to this paper I got to know that there are two kinds RNN: Elman-type and Jordan-type. The only difference is the context nodes of Jordan-type RNN are fed from the output layer (a softmax function) instead of from the hidden layer(a sigmoid function). Seems that the softmax layer can store and convey more information than the sigmoid layer as it contains more nodes. The experiment results also confirm that the Jordan-RNN can offer slightly higher performance than the Elman-RNN.
Besides the comparison between these two RNNs, this work also tests the influence of using pre-trained embeddings. We know that the word vector learned from large corpus may result in a dramatic improvement on NLP problems (see (Collobert et al., 2011)). This paper confirms this idea. The word vectors from SENNA with fine-tuning brings out the best performance (2% better than RNNLM and randomly initialized). Does the SENNA method really capture a better nature of language?
And the detailed comparison is listed below. As the task is relatively easy, most models can achieve a roughly good performance. The CRF is not far behind the best model (Bi-directional Jordan-type RNN).

2.2 Using Recurrent Neural Networks for Slot Filling in Spoken Language Understanding
This paper is a follow-up paper of the last one (Mesnil et al., 2013). Besides the content from last paper, the main contribution of this paper is it tries to incorporate the benefits of CRF into RNN, which can “perform global sequence optimization using tag level features” and avoid “the same label bias problem”. Thus two methods are proposed here. The first is called Slot Language Models, which applying a Markov model at the top of RNN (observation likelihood) and language model (state transition probability). Another method is called Recurrent CRF, in which uses the objective function of a CRF and trains the transition probabilities and RNN parameters jointly.
Originally, given the input word sequence \(L^N_1=l_1,\ldots,l_N\) , the linear-chain CRF models the conditional propability of a slot sequence \(S_1^N = s_1, \ldots, s_N\) as follows:
\[P(S_1^N|L_1^N) = \frac{1}{Z}\prod^{N}_{t=1}\exp^{H(s_{t-1},s_t,l^{t+d}_{t-d})}\]where
\[H(s_{t-1},s_t,l^{t+d}_{t-d})=\sum^M_{m=1}\lambda_mh_m(s_{t-1},s_t,l^{t+d}_{t-d})\]and \(h_m(s_{t-1},s_t,l^{t+d}_{t-d})\) are features extracted from the current and previous states \(s_t\) and \(s_{t-1}\), plus a window of words around the current word \(l_t\) with a window size of \(2d+1\).
The R-CRF objective function is almost the same as Equation(1) except for the features are from RNN. That is, the features part, \(h_m(s_{t-1},s_t,l^{t+d}_{t-d})\) , in CRF objective function is changed to the form below:
\[\begin{align} H(s_{t-1},s_t,l^{t+d}_{t-d}) & =\sum^M_{m=1}\lambda_mh_m(s_{t-1},s_t,l^{t+d}_{0}) \\ & =\sum^P_{p=1}\lambda_ph_p(s_{t-1},s_t)+\sum_{q=1}^Q\lambda_qh_q(s_t,l^{t+d}_{0}) \end{align}\]where the first term is transition feature and the second term is tag-specific feature.
The models are evaluated with three datasets: the ATIS, Movies and Entertainment. The later two are not public yet. The influence of the proposed models are not very significant. Compared to naive RNNs, the change of Slot Language Model on ATIS is very little, but it improves large on the Entertainment datasets. The R-CRF model gains 96.46% F1 score on ATIS, with the help of Named Entity information as additional features. In summary, the combination of RNN and CRF is not very successful. We can see very slight advantage on the new models. We may seek for other ways to improve the RNNs on labeling task.
2.3 Spoken Language Undertanding Using Long Short-Term Memory Neural Networks
This work is roughly simple, almost everything is similar to the last one except for replacing the model to LSTM. The result is shown below:
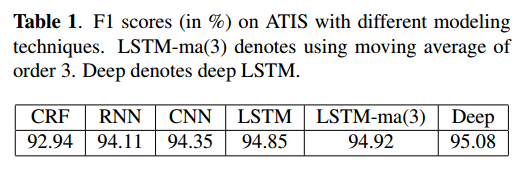
The highest performance is achieved by the Deep LSTM, a multiple-layer structure by stacking two LSTMs on the top of each other. The LSTM-ma(3) explores the similar idea of (Mesnil et al., 2015), to exploit the dependency of predicted labels, which can be treated as another short-term memory.
2.4 Recurrent Neural Netwoks with External Memory for Language Understanding
One work similar to the last one, by extending the architecture of Neural Networks. Inspired to the Neural Turing Machine, this work made an attempt on planting an external memory module inside the network (a complicated LSTM), to better store and retrieve the long-term memory. Only ATIS was used for evaluation and achieved slight improvement. I do think this is a good direction, enhancing RNN by introducing sophisticated inner architectures. But maybe ATIS is too small and trivial to evaluate the performance of big models.
2.5 Is it time to switch to Word Embedding and Recurrent Neural Networks for Spoken Language Understanding?
After seeing some many papers about RNN, you must think that the new model would end the dominance of CRF on labeling task. But this paper cools us down with several findings. The authors compared three algorithm (CRF, RNN and AdaBoost.MH over bonsai trees) on two publicly available corpora for SLU.

Slot tagging performance obtained with several learning algorithms on ATIS and MEDIA. hdn stands for hidden neurons.
The experimental result on ATIS is quite consistent with the previous work. But on MEDIA, we saw a huge gap between RNN and CRF on both performance and speed. However this paper didn’t give any detailed explanation about this result. But we see that the speed advantage of CRF is quite obvious. And the comparison on different dataset is necessary.
References
- Raymond, C., & Riccardi, G. (2007). Generative and discriminative algorithms for spoken language understanding. INTERSPEECH, 1605–1608.
- Serban, I. V., Lowe, R., Charlin, L., & Pineau, J. (2015). A survey of available corpora for building data-driven dialogue systems. ArXiv Preprint ArXiv:1512.05742.
- Mesnil, G., He, X., Deng, L., & Bengio, Y. (2013). Investigation of recurrent-neural-network architectures and learning methods for spoken language understanding. INTERSPEECH, 3771–3775.
- Mesnil, G., Dauphin, Y., Yao, K., Bengio, Y., Deng, L., Hakkani-Tur, D., He, X., Heck, L., Tur, G., Yu, D., & others. (2015). Using recurrent neural networks for slot filling in spoken language understanding. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 23(3), 530–539.
- Yao, K., Peng, B., Zhang, Y., Yu, D., Zweig, G., & Shi, Y. (2014). Spoken language understanding using long short-term memory neural networks. Spoken Language Technology Workshop (SLT), 2014 IEEE, 189–194.
- Guo, D., Tur, G., Yih, W.-tau, & Zweig, G. (2014). Joint semantic utterance classification and slot filling with recursive neural networks. Spoken Language Technology Workshop (SLT), 2014 IEEE, 554–559.
- Peng, B., Yao, K., Jing, L., & Wong, K.-F. (2015). Recurrent neural networks with external memory for spoken language understanding. National CCF Conference on Natural Language Processing and Chinese Computing, 25–35.
- Vukotic, V., Raymond, C., & Gravier, G. (2015). Is it time to switch to Word Embedding and Recurrent Neural Networks for Spoken Language Understanding? InterSpeech.
- Kurata, G., Xiang, B., Zhou, B., & Yu, M. (2016). Leveraging Sentence-level Information with Encoder LSTM for Natural Language Understanding. ArXiv Preprint ArXiv:1601.01530.
- Collobert, R., Weston, J., Bottou, L., Karlen, M., Kavukcuoglu, K., & Kuksa, P. (2011). Natural language processing (almost) from scratch. Journal of Machine Learning Research, 12(Aug), 2493–2537.
-
Source of figure: http://karpathy.github.io/2015/05/21/rnn-effectiveness/ ↩