Research talk 10 - Structured Prediction and Deep Learning
Andrew McCallum is a Professor at University of Massachusetts Amherst. His well-known work Conditional Random Fields has been widely used in Natural Language Processing as well as other domains. His recent research interest is regarding the intersection of structured prediction and deep learning, hoping to extend the current success of deep learning to more NLP applications.

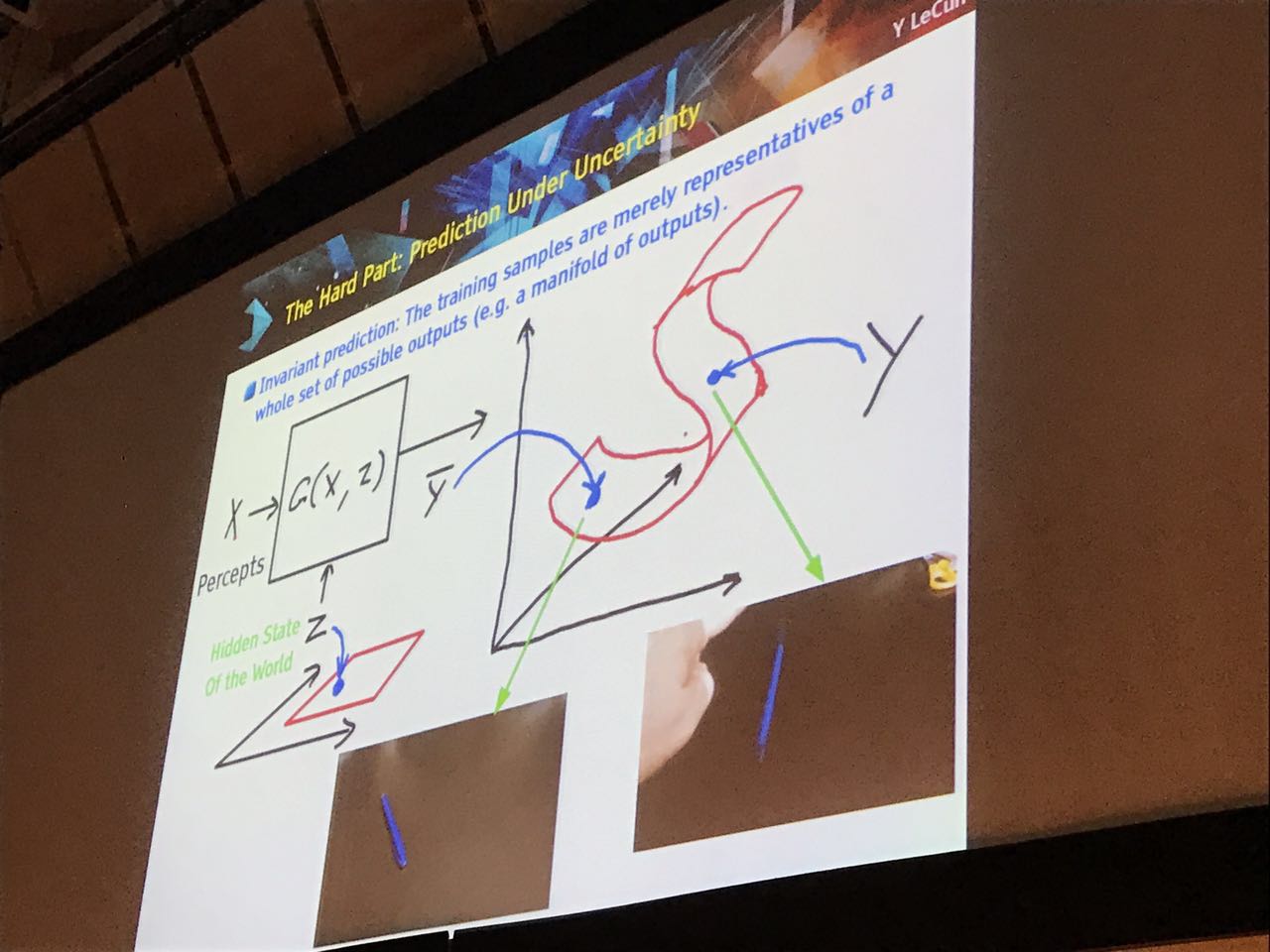
Structured prediction includes a bunch of common tasks in natural language processing, like spam filtering, chinese word segmentation and multi-label document/image classification. In all these prediction tasks, the long-range dependency plays a critical role and should be considered carefully. So far the most successes of structured prediction are achieved by graphical models, and CRF is one special graphical model which is proved to be quite powerful. Actually the graphical model is very related to neural networks, and in some way it could be improved by incorporating the deep learning thought.

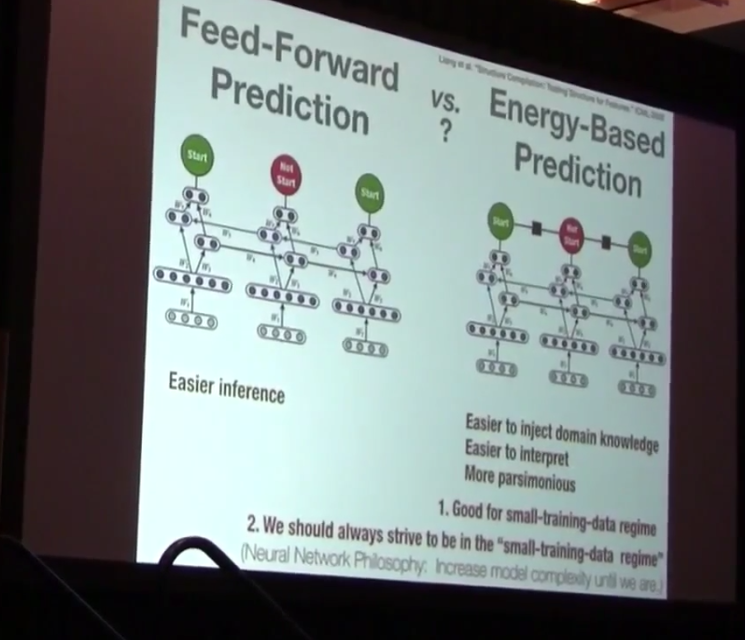
There are multiple ways to apply the deep learning on structured prediction. Firstly we can just make use of the feature representation in deep neural networks, like directly impose the deep features and predict each target dependently. However all these methods have shortcomings like doesn’t consider global dependency, hard to optimize. So in this lecture, he mainly introduced their work called “structured prediction energy networks”, which uses a deep architecture to learn rich representations of output dependencies. Most importantly, their model replaces the factors in the factor graph with a neural network yielding a scalar energy. Interestingly, this idea is also appropriate to multiple output scenarios like keyphrase prediction.
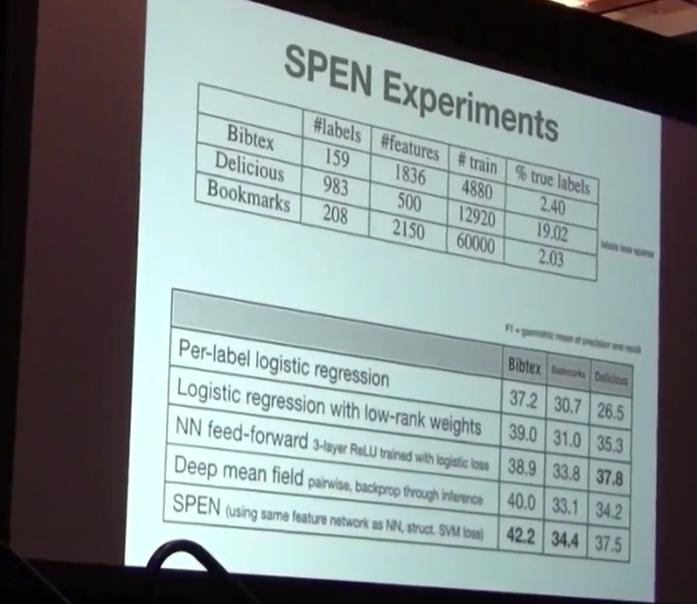
Basically, considering the dependency of multiple outputs is a good idea which is borrowed from some graphical models, and the results demonstrate it’s power on most important structured prediction tasks. It’s very exciting to see the incorporation of graphical model and neural networks, and this may bring breakthrough on explainable deep models.